Why didn't Clojure work concurrently in Vagrant?
I recently couldn’t work out why Clojure was not working concurrently in a Vagrant box. I didn’t solve the problem, but I learned many things, and here are some of them.
I use Vagrant for most things I do
I love Vagrant. I love being able to put things down and pick them up where I left off, without having to recreate environments. I do not have a good memory, and the Vagrantfile is built-in documentation. I create a Vagrantfile for almost every side project I do.
Of course, this means I sometimes (or often…) end up going down a rabbithole that has very little to do with the actual side project itself. However, these are usually most entertaining, and I learn things. Here is one rabbithole and what I learned.
I could not replicate a concurrency gain
I was working my way through Seven Concurrency Models in Seven Weeks and running some code examples on my Vagrant machine, and I found that a promised speed-up by using a function that supported concurrency did not materialise.
In a Leiningen REPL I ran:
(ns sum.core
(:require [clojure.core.reducers :as r]))
(defn sum [numbers]
(reduce + numbers))
(defn parallel-sum [numbers]
(r/fold + numbers))
(def numbers (into [] (range 0 10000000)))
(time (sum numbers))
(time (sum numbers))
(time (parallel-sum numbers))
(time (parallel-sum numbers))
That is, I define a function called sum which uses reduce, and one called parallel-sum that uses fold. I then use time to see how long each function takes to sum a range of numbers from 0 to 10,000,000. To quote the book, we run each of the timing functions twice “to give the just-in-time optimizer a chance to kick in and get a representative time”.
reduce is not parallel, but fold can be, and according to the author, on his four-core Mac, the fold function gave around a 2.5x speed-up.
However, on my Vagrant box, the two functions ran in approximately the same length of time.
I eventually asked for help on Twitter
After quite a bit of investigation myself, including correcting some foolish errors, I was not able to work out why this wasn’t working. Vagrant could see all four of the cores ((.availableProcessors (Runtime/getRuntime)) showed it could see 4) but the allegedly parallel code was no faster.
I figured this must be something to do with Vagrant, and I was committed to getting it all working on my Vagrant machine, if I could.
On @borkdude’s suggestion I wrote it up in a gist.
I got some very helpful responses.
It could be how VirtualBox creates CPUs
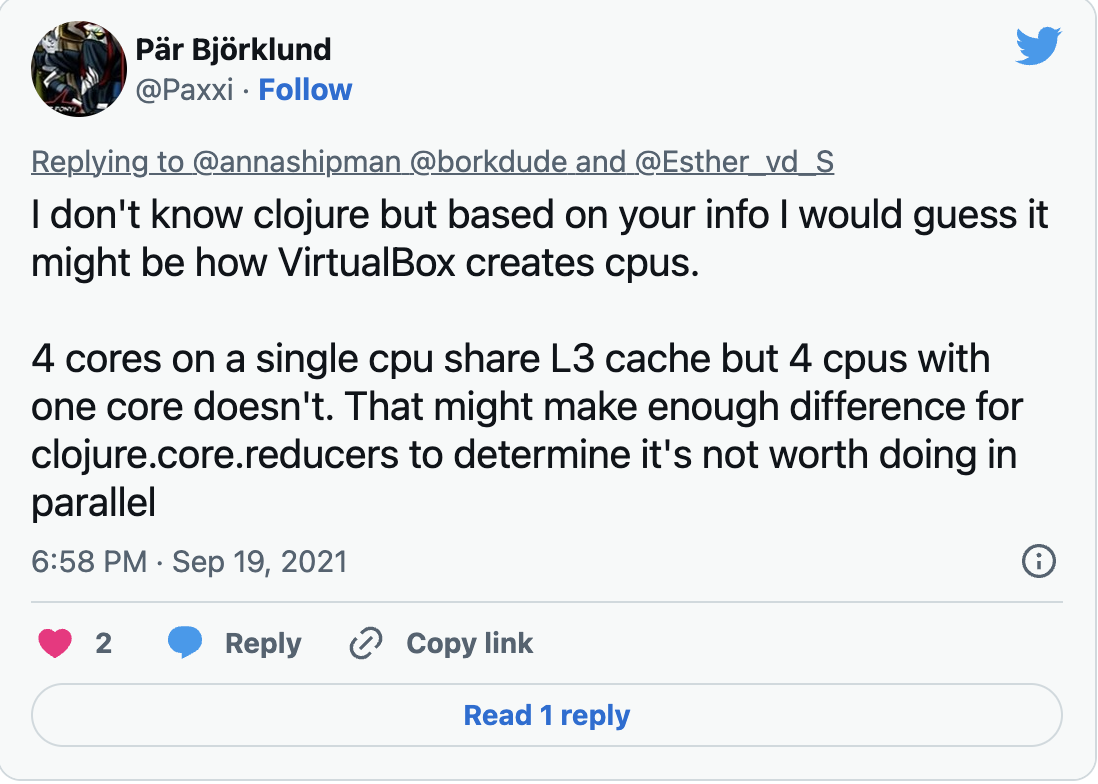
Text in image Tweet from Pär Björklund (@Paxxi): “I don’t know clojure but based on your info I would guess it might be how VirtualBox creates cpus. 4 cores on a single cpu share L3 cache but 4 cpus with one core doesn’t. That might make enough difference for clojure.core.reducers to determine it’s not worth doing in parallel
Until I read this tweet, I had not consciously realised that CPUs and cores were different things. Sometimes the two terms are used interchangeably – incorrectly, I now know.
A CPU is made up of one or more cores, an input and output management unit, and some other things. The cores are the parts that actually do the work of executing instructions, so multiple cores allow the CPU (in theory at least) to carry out multiple instructions at once. A dual-core machine is not a computer with two CPUs, it’s a computer with one CPU that has two cores. It is also possible for computers to have multiple CPUs, either single-core or multi-core.
CPUs have caches to speed up access to memory; L1, L2 and L3. The details vary between manufacturers and chips, but the L3 cache is the biggest CPU cache and is usually built between the CPU and the RAM. Each core usually has its own L1 cache and possibly L2 cache, though L2 may be shared. L3 cache is usually shared between the cores.
So Pär Björklund’s suggestion was that if VirtualBox created the multiple CPUs as CPUs rather than cores, the L3 cache wouldn’t be shared, so parallelising would not produce much of an efficiency gain, and therefore Clojure may decide not to do it.
The investigation into whether my virtual machine has multiple cores or multiple CPUs involved much unpicking. Vagrant’s docs refer to setting CPUs. It links to the VirtualBox manual which refers also to CPUs (“--cpus <cpucount>: Sets the number of virtual CPUs for the virtual machine”) but refers you on to another part of the manual which reveals that it’s actually CPU cores: “Sets the number of virtual CPU cores the guest OSes can see.”
From this, I learned that I should not have set my guest VM to have 4 CPUs on my dual-core host, though not unexpectedly, making that change did not affect the speed of the parallel-sum function.
I did establish that it looks like VirtualBox is creating multiple cores rather than multiple CPUs, so in theory they may be sharing L3 cache, though I can’t say definitively whether they are. In any case, it doesn’t seem that I have any control over it.
Digging into this suggestion led me to some very interesting learnings about the structure of computers, and might actually be the root of the problem, but even if it is, it’s not clear if I can solve it. So I moved on to other suggestions.
It could be that there are not enough threads
Dak asked what I had set the virtual CPUs and CPU cap to:
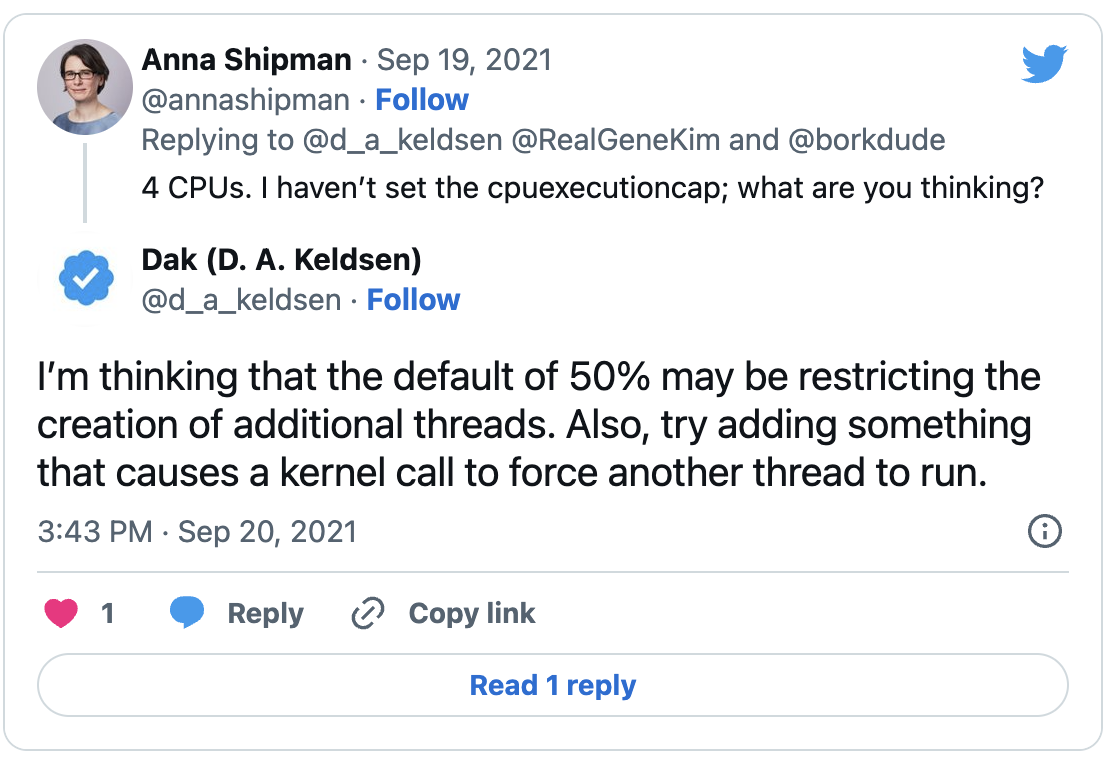
The CPU execution cap controls how much of the host’s CPU time a virtual CPU can use. The VirtualBox documentation doesn’t appear to say what the default is, though the suggestion above is that its 50%, which makes sense.
However, explicitly setting it to 50% and then 100% on my VM made no difference. At 100% it was faster, but there was still no difference between the speed of reduce and fold.
The idea of making a kernel call is to call an interrupt to test whether control can pass from thread to thread. A kernel interrupt would be higher priority than my Clojure function; so if I called a kernel interrupt and it wasn’t successful, I would know threading is not working as expected in my VM.
I wasn’t sure how to do this. In Java, I could call the interrupt() method of Thread, but in Clojure, all the threading is being done under the hood. However, in any case, we know that there is enough CPU being allowed for the guest to create new threads because some of the other threading in the book does work. Relevantly, the Java threading examples work, and Clojure runs on the JVM.
Even though it looks like this is not the cause of the problem, it’s a very interesting suggestion and helped consolidate my understanding of how threading works.
It could be to do with the JVM Garbage Collection
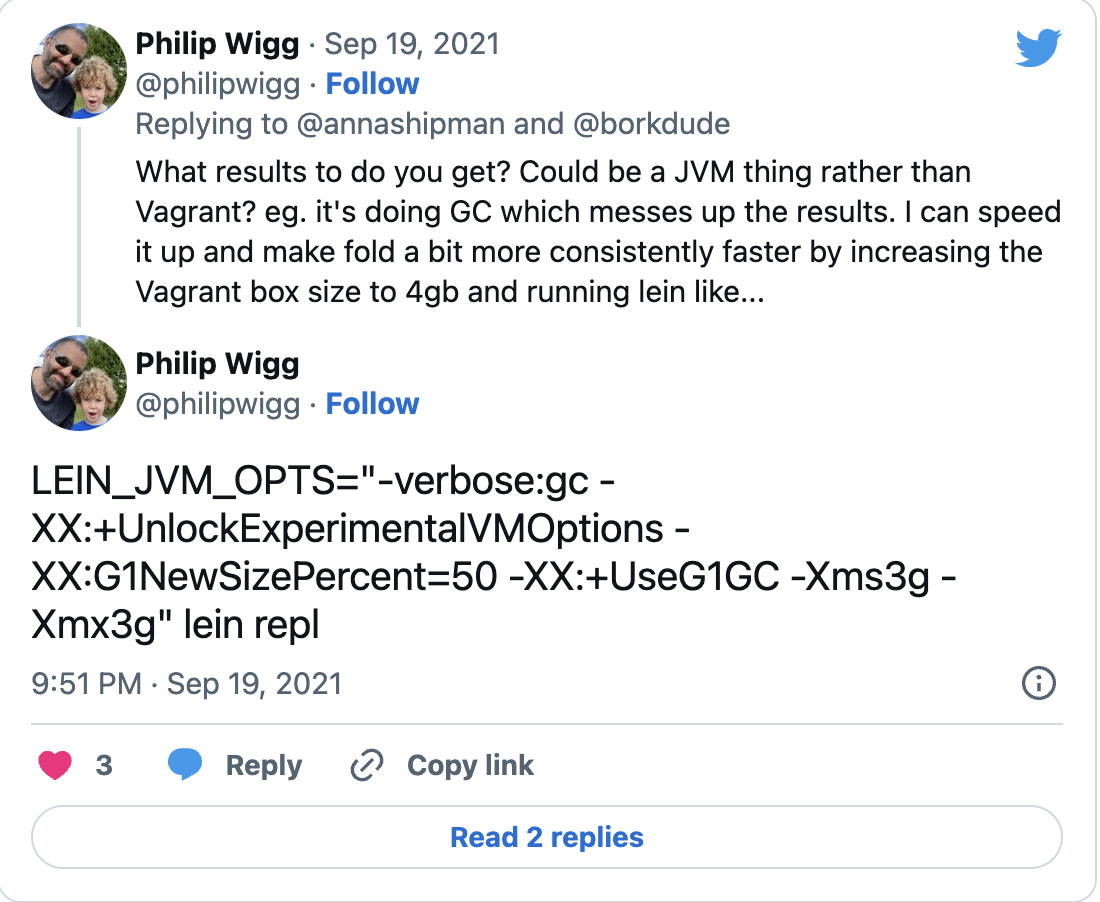
Text in image Tweet from @philipwigg: “What results to do you get? Could be a JVM thing rather than Vagrant? eg. it’s doing GC which messes up the results. I can speed it up and make fold a bit more consistently faster by increasing the Vagrant box size to 4gb and running lein like…[followed by the command I outline below]”
Philip Wigg had the answer that had the most impact. He suggested that it might be the JVM Garbage Collection that was messing with the results.
Instead of starting the Leiningen REPL with lein repl, start it with LEIN_JVM_OPTS="-verbose:gc -XX:+UnlockExperimentalVMOptions -XX:G1NewSizePercent=50 -XX:+UseG1GC -Xms3g -Xmx3g" lein repl.
To unpick this:
LEIN_JVM_OPTS: set options for the leiningen JVMverbose:gc: make the garbage collector verboseXX:+UnlockExperimentalVMOptions: the version of Java on my VM is Java 8, so the following are all experimental at that stageXX:G1NewSizePercent=50: set the percentage of the heap to use as the minimum for the young generation sizeXX:+UseG1GC: explicitly use the Garbage First Garbage Collector. This is now the default, but was not for Java 8Xms3g -Xmx3g: set the initial and max heap size
While looking into this I found this very useful and interesting article about garbage collection, most of which I’d forgotten about since my time as a Java programmer, many years ago.
The theory here is that on the host, the JVM has access to more RAM, but on the smaller VM, without this tuning, it has to keep doing garbage collection, which slows things down.
This did make parallel-sum faster for me. And here are his results:
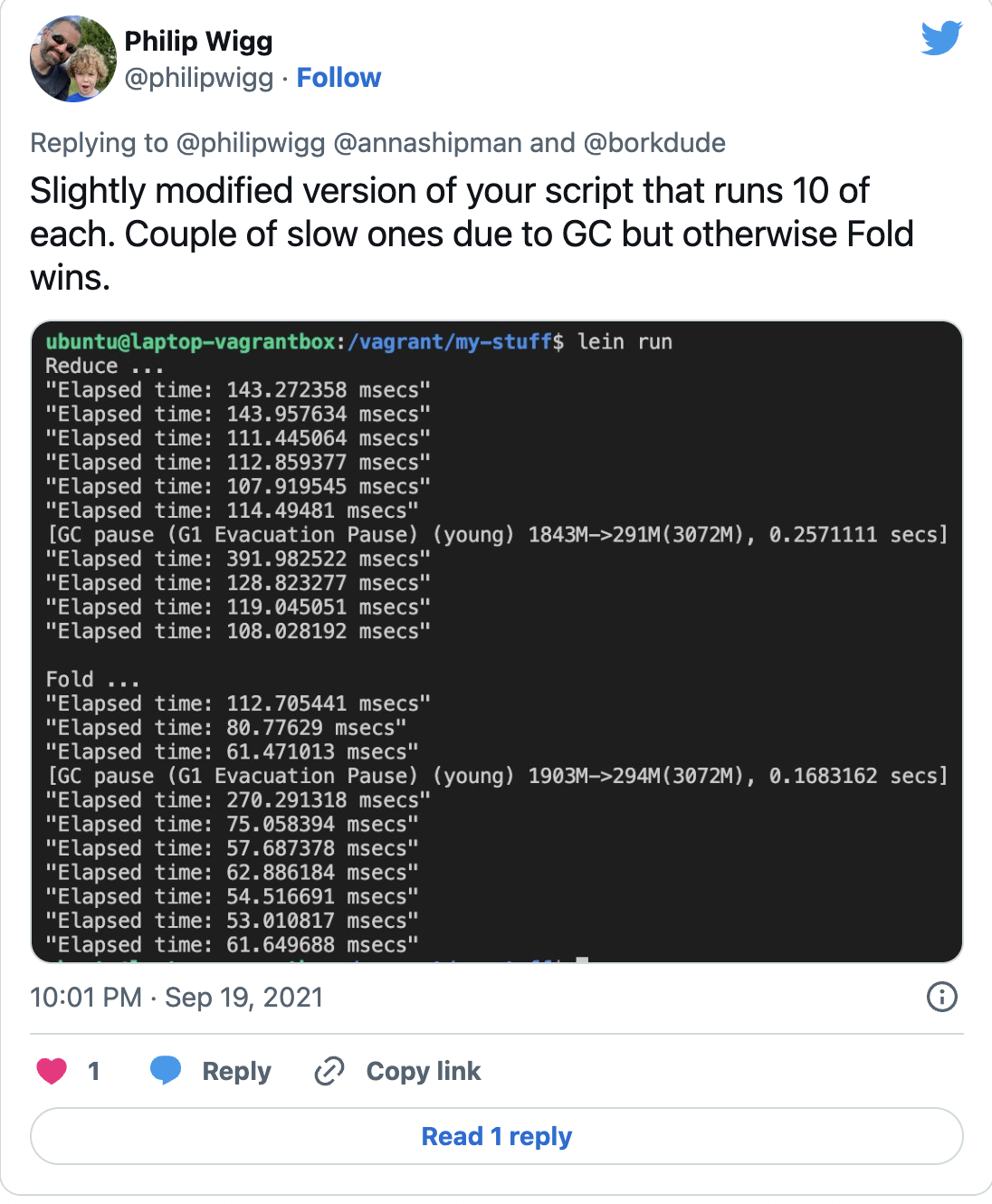
However, I never got to the promised 2.5x speed-up, and I later found that this did not even consistently speed up my results. But once again, it was very entertaining and I learned (and remembered!) some interesting things.
I never got to the bottom of it!
This was a very interesting digression. I learned a lot that I didn’t know, some of it about concurrency, and some about how computers work, always a fascinating topic.
Of course, I didn’t actually solve my problem! An easy way to have replicated these concurrency gains would have been to install Clojure and Leiningen on my Mac and run it like that. But one of the other reasons I like Vagrant is that I don’t like to install things on my computer that I don’t need. I don’t even have Java on this computer. So installing all that on my computer would have taken away another of the main benefits of using Vagrant for me.
If you want to follow along the code examples in the Seven concurrency models book, you can use my Vagrantfile to run some of the examples. But be warned, the Clojure ones do not all work as expected. Hopefully you now have some hints about why!
Edit: It could be a problem with the JDK that VirtualBox installs
After publishing this blog post, Linus Ericsson suggested another theory:
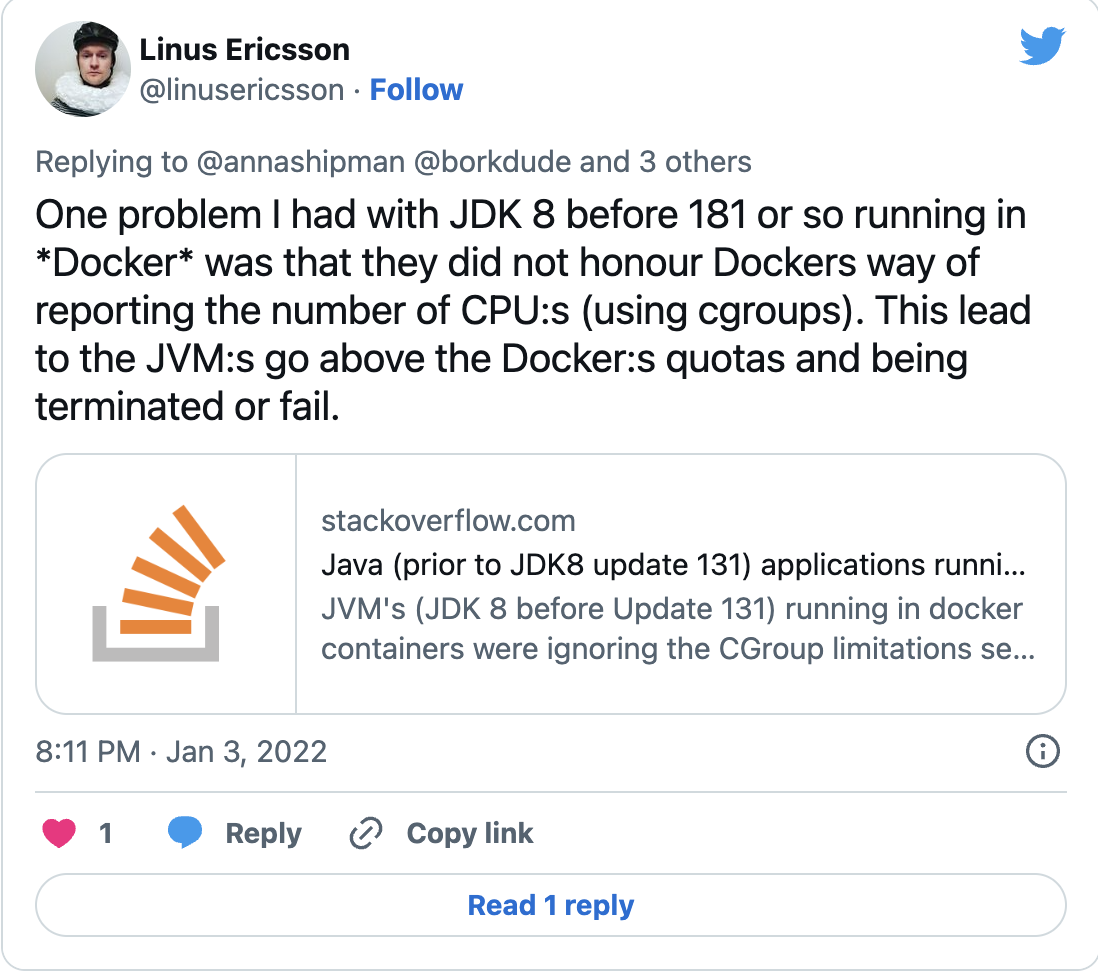
Text in images Tweet 1 of 3 @linusericsson: One problem I had with JDK 8 before 181 or so running in *Docker* was that they did not honour Dockers way of reporting the number of CPU:s (using cgroups). This lead to the JVM:s go above the Docker:s quotas and being terminated or fail. link to Stack overflow
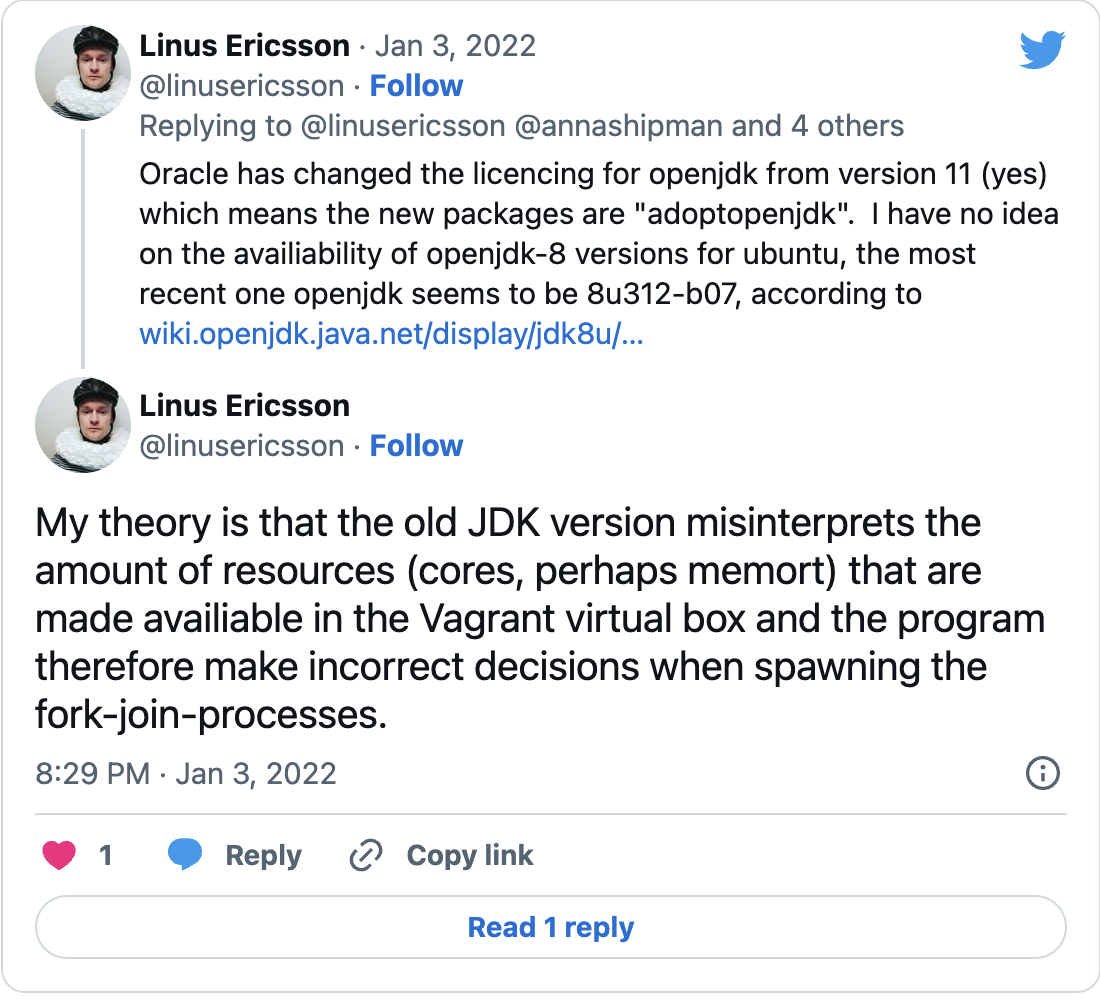
Tweet 2 of 3 @linusericson: “Oracle has changed the licencing for openjdk from version 11 (yes) which means the new packages are “adoptopenjdk”. I have no idea on the availiability of openjdk-8 versions for ubuntu, the most recent one openjdk seems to be 8u312-b07, according to https://wiki.openjdk.org/display/jdk8u/Main
Tweet 3 of 3 @linusericsson: “My theory is that the old JDK version misinterprets the amount of resources (cores, perhaps memort) that are made availiable in the Vagrant virtual box and the program therefore make incorrect decisions when spawning the fork-join-processes.”
This is very plausible. Unfortunately, the default JDK for the OS I’m running is 1.8.0_292, and the latest available is 1.8.0_312: not a big difference, and installing that did not solve my problem. So again, this could be the solution but I cannot fix it if so.
If you’d like to be notified when I publish a new post, and possibly receive occasional announcements, sign up to my mailing list: